
最新人工智能(AI)驱动系统对算力和输入输出(IO)的需求,已远超工艺节点升级所能承载的范畴。若一味追求更大尺寸的芯片(逼近掩模版尺寸极限),会导致良率下滑、成本攀升。此外,部分模拟电路和IO功能难以从先进工艺节点中获得显著收益。而迁移到新工艺节点,实则是让这些功能运行在成本陡增的晶圆上,却仅换来微乎其微的回报,可谓得不偿失。同时,技术创新节奏日益加快,使得新一代片上系统(SoC)的迭代周期从传统的3-4年缩短至1-2年。
据IDtechEx报道,到2035年,芯粒市场规模将达到4110亿美元。芯粒技术通过将SoC功能分解为更小的异构或同质芯片(即“芯粒”),再将芯粒集成到单系统级封装(SIP)中,可满足持续增长的算力和IO带宽需求,其总硅片面积可超过单个SoC的掩模版尺寸。SIP不仅包含传统封装基板,还可采用中介层实现更高布线密度,从而能够在单个标准或先进封装中显著提升功能集成度。图1展示了在高性能计算应用中,通过UCIe Die-to-Die接口互联的芯粒的部分潜在应用场景。

图1.采用UCIe IP实现Die-to-Die连接的HPC芯粒示例
芯粒市场的愿景是:开发者能够通过混合搭配现成的芯粒快速构建系统。如此一来,设计团队可专注于产品的差异化创新,而通用计算与IO功能则由芯粒承载。在其他领域,标准不统一和功能碎片化的问题仍阻碍着这一愿景的落地。尽管UCIe标准、ARM CSA规范及各类汽车联盟都已取得一定进展,但尚不足以支撑行业所期待的芯粒市场格局。本文将深入探讨系统开发者在芯粒设计与集成过程中面临的部分关键问题及决策考量。
01系统划分
设计团队需要考虑的首要问题是:设计中应包含哪些功能模块与功能,以及如何将这些功能划分到不同的芯粒中。此外,开发者还需为每个模块选择高效的半导体工艺节点。一种常见的总体划分方式是,将计算芯片、输入输出(IO)芯片和存储功能分别部署在不同的芯粒上。接下来要做的是,在延迟、带宽和功耗之间进行权衡,具体均取决于工艺节点的选择和芯粒的划分方式。
02工艺节点的选择
AI加速器中的计算芯片可能适合采用最新的工艺节点,以优化性能和功耗;但在最新工艺节点中实现缓存存储器可能并非理想选择。缓存或许可以集成在同一芯片上,但静态随机存取存储器(SRAM)在最新工艺节点中的扩展性可能远不及逻辑电路,因此在成本更低的节点上实现SRAM会更具效益。此外,通过2.5D Die-to-Die接口来满足芯片外数据传输的延迟要求可能不太合适。一种可行方案是采用3D集成架构:计算芯片采用最新的N节点工艺,而SRAM和IO芯片则采用N-1或N-2节点工艺。
模拟功能或IO接口功能(PCIe、以太网等)对延迟的容忍度可能更高,因此适合在独立的芯粒中实现,并通过UCIe接口与主芯片连接。主芯粒则可采用较旧的工艺节点以节约成本。
03Die-to-Die连接考量因素
UCIe已成为芯粒间Die-to-Die连接的实际标准,但选择UCIe配置时需考量诸多因素。开发者需根据芯粒的工作任务明确带宽需求,其中既包括主频段数据的带宽,也涵盖用于控制与管理的侧信道数据带宽。以AI服务器的IO芯粒应用为例,UCIe的带宽需求与以太网、UALink或PCIe等接口IP息息相关。开发者需做出多项决策,比如每条通道的数据速率;是采用支持更长传输距离的有机基板(UCIe标准方案),还是采用超小前端布局与具有超小凸点间距的先进封装(UCIe高级方案)。此外,还需在数据速率(范围为16G至64G)与满足芯片前端限制所需的通道数量之间进行权衡。可用的前端布局可能会根据接口IP的物理层(PHY)布局而变化。根据芯粒的目标尺寸和/或深宽比,开发者可选择将PHY布置在芯片边缘的单排中;另一种方案是将PHY按列双层堆叠,以牺牲PHY区域深度为代价,将前端布局缩减一半。大多数UCIe应用采用串流接口,开发者必须确定从UCIe串流到接口IP的桥接方式,可选方案包括AXI、ARM CXS或即将推出的PXS等标准。此外,还需考虑如何在不浪费带宽的前提下将数据封装到可用资源中、执行时钟交叉功能,并决定数据是从UCIe直接点对点传输到接口IP,还是先传输至中间的片上网络(NOC)以提升芯粒内部连接的灵活性。
04先进封装技术:新能力与新挑战并存
如今,封装技术受到了前所未有的关注。这些技术进步在带来巨大机遇的同时,也为单个芯粒或Multi-Die设计中多个芯粒的开发带来了更多挑战。
开发者需要确定在Multi-Die设计中芯粒的互联方式。与包含中介层或带硅桥中介层的2.5D架构相比,有机基板成本更低,设计周期也更短。对于更先进的应用场景,可能需要中间的中介层来满足所需的互联密度、电源/接地及信号路径要求。一旦确定采用中介层,就必须选择成熟的硅中介层、新型有机基板重布线层(RDL)中介层,或带硅桥的RDL中介层,以根据需求提供更高密度的互联。硅中介层为成熟技术,但尺寸越大成本越高,且受限于材质脆性,尺寸存在局限。RDL中介层则旨在降低成本,并支持更大尺寸,以集成包含更大硅片面积的大型系统。无论选择哪种方案,开发者都面临新的挑战,包括机械外形尺寸、信号完整性与电源完整性分析、单个芯粒的热分析及其间的相互作用。此外,凸点规划和晶圆探针布局的复杂性也随之增加,需要协调芯粒、封装与测试要求之间的适配性。即便在同一类型的基板衬底或中介层中,凸点间距也可能存在差异,衬底的典型凸点间距范围为110至150微米,而中介层上使用的微凸点间距为25至55微米。正如图2所强调的,若加入3D芯片堆叠,差异会愈发显著。
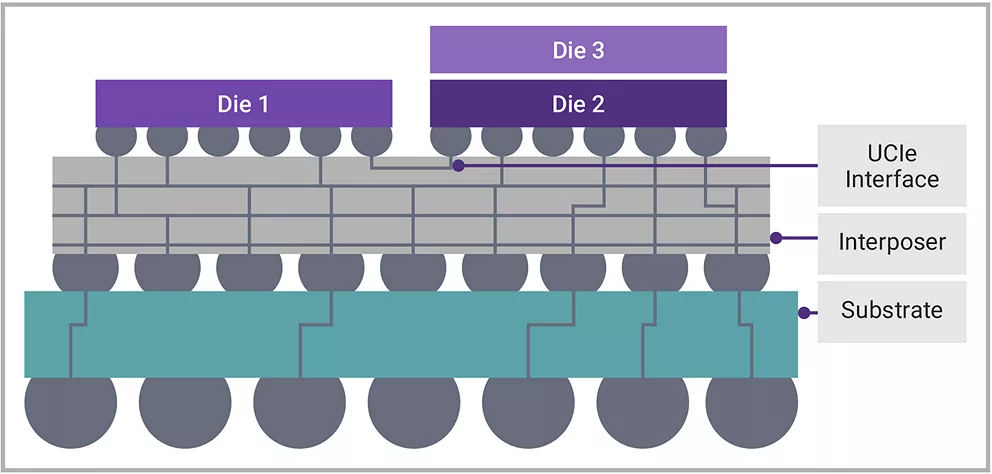
图2.3.5D封装示例:通过中介层连接3D芯片堆叠与另一颗2D芯片
封装面临的挑战还包括测试规划,例如通过晶圆探针实现芯粒的可访问性,以确保产出已知合格的芯片(KGD);利用IEEE 1838协议和多芯粒测试服务器,对无法通过外部引脚直接访问的芯片进行测试。
05设计与验证:安全性考量
IP集成面临诸多挑战,包括互操作性、验证及安全性等方面的问题。
当开发者完成异构或同构芯粒的系统划分后,接下来要面对的挑战就是设计安全维度的考量。在Multi-Die设计中,需要防御的攻击面范围更广。首要问题是提供认证功能,以验证每个芯粒的合法性。其次,根据终端应用场景,开发者可能需要构建信任根,用于处理敏感数据,还可能需要在系统间传递密钥以提供数据加密服务。此外,开发者还可考虑采用安全启动流程,从硬件和固件层面防止外部篡改。同时,必须考虑为关键接口上传输的数据提供保护,例如PCIe与CXL的完整性和数据加密(IDE)功能、DDR与LPDDR的内嵌存储加密(IME)功能、以太网的MACsec功能等。另一种可行方案是支持ARM的机密计算架构(CCA)。
系统级仿真、模拟与原型设计是开发过程中的关键步骤,可确保芯片的功能与性能达标,实现一次性交付成功。协同设计需涵盖芯片、软件与系统组件,以实现最佳的集成与效率,使开发者能在芯片可用前,提前开始软件开发工作。
06结语
将概念和构想转化为Multi-Die设计,需综合考量诸多因素,且离不开深厚的经验积累。新思科技提供业界丰富且基于标准的接口IP产品组合及IP子系统集成服务,能够交付可直接集成的芯粒子系统。开发者可使用新思科技的系统解决方案设计服务,并借助对新思科技EDA与IP产品有深入了解的生态合作伙伴的力量,从而加速开发进程,确保芯片、封装与软件产品的优化集成。目前,开发者可与新思科技展开合作,探讨从概念构想、架构设计、IP选择、流程与方法,到RTL设计、IP集成、物理实现、封装设计、晶圆厂管理等各个环节,也可选择与新思科技携手,采用端到端全流程设计方案。依托新思科技的专业能力与技术服务,开发者能够聚焦自身核心优势,将设计中的其他环节交由相关领域的专家,从而快速、可靠地推进产品上市。







