我院孙华军/缪向水教授课题组在基于忆阻器的语言模型电路级实现与算法协同设计方面取得重要突破,相关研究成果以题为《Memristor-Based Circuit Implementation and Circuitry Optimized Algorithm for Mamba Language Network》的论文6月26日发表在国际电路与系统顶级期刊 IEEE Transactions on Circuits and Systems I: Regular Papers (IEEE TCAS-I) 上。我校为论文第一作者和通讯作者单位,我院张峻铭和南加州大学盛哲远为共同第一作者,孙华军教授为通讯作者。
01 问题阐述
近年来,Transformer模型成为主流语言模型架构,广泛应用于自然语言处理与视觉任务,但其基于自注意力机制的计算复杂度呈二次增长,需要庞大的资源开销,限制了其在边缘和嵌入式场景下的应用。新兴的Mamba语言模型通过选择性状态空间模型(Selective SSM)有效降低计算复杂度与处理长序列时所需的资源开销,逐渐展现出替代Transformer的潜力。
然而,Mamba模型因其计算结构复杂、状态变量耦合性强,尚未实现基于忆阻器电路级的完整部署。同时,缺乏面向电路级的并行扫描+硬件感知化推理算法。
为突破上述难点,团队针对在电路层面实现Mamba模型的关键挑战——复杂矩阵计算与状态存储以及并行推理与隐状态跨周期迁移——展开研究。
02 解决问题
提出了一种基于忆阻器的Mamba语言模型完整电路实现方案,并首次设计了一套电路感知并行扫描推理算法(Computing-in-Memory Parallel-Aware Algorithm),在结构与数据流上实现端到端加速:
全电路实现(Computing Architecture):设计标准1T1M忆阻交叉阵列与一维深度可分卷积忆阻阵列,覆盖Mamba的投影,一维卷积等矩阵型运算,避免权重与计算分离引入额外的存储与I/O开销。
Implicit latent state “存内计算”电路:提出CIM隐式潜态模块,实现隐状态计算,存储与跨周期迁移,配合SiLU激活、RMS归一化等功能电路,使推理过程全模拟化、显著减少ADC/DAC与中间存储。
计算-存内并行感知算法:将Mamba原生并行扫描与硬件感知融合到电路级,实现顺序输入、并行输出与隐式潜态的自迁移;突破了Mamba的隐式潜态无法并行的缺陷,进一步扩展并行度。
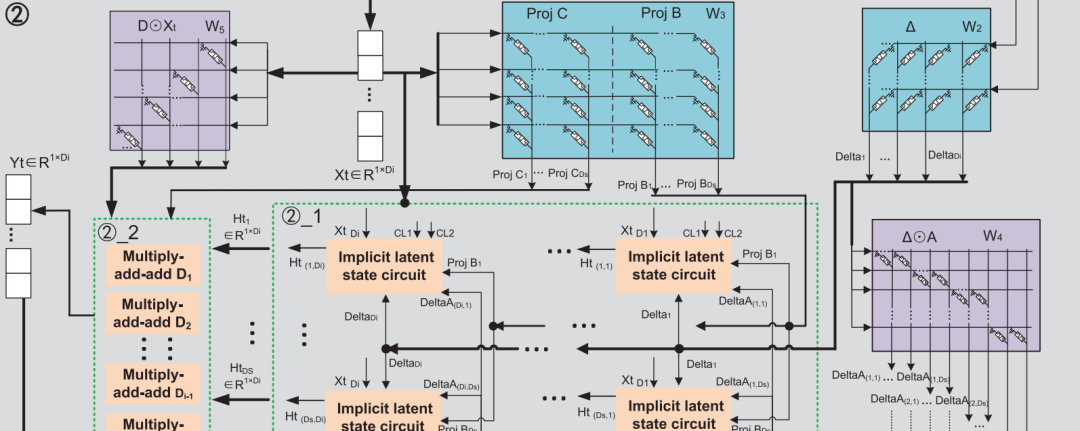
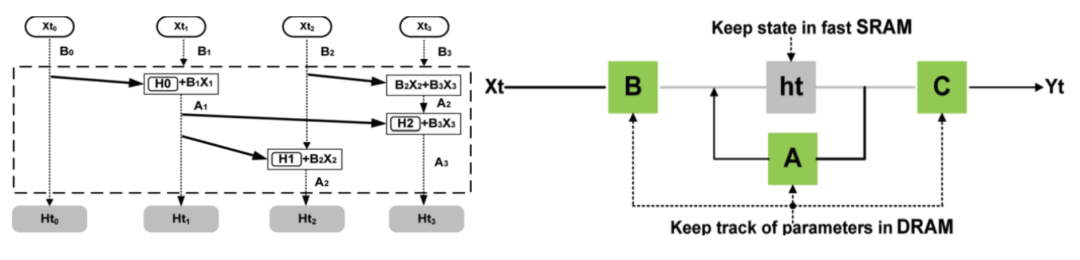
图一:Mamba推理电路与hardware-aware parallel 算法示意图
03 成果亮点与测试验证
实现了端到端的电路级句子生成任务,验证模型电路从输入词嵌入到输出序列的全链路正确性,同时所提出的电路级并行感知优化算法使得计算总时间变为原来的1/3,验证了其并行 输出的能力。在精度与鲁棒性方面:模拟计算与标准结果对比,平均准确率可达95.98%;在9位权重量化下平均准确率仍然可达约86.58%。在加入15%白噪声干扰下仍保持输出稳定,具备良好鲁棒性。单个token生成平均功耗约为585.32 mW,在当前模拟电路体系下表现优异,展现出向低功耗嵌入式系统迁移的潜力。与Transformer及RNN等传统模型相比,该实现显著降低了计算复杂度与推理时延,为大规模电路集成提供了新的方向。
结语
该工作展示了Mamba语言模型在硬件级特别是基于忆阻电路的可实现性与优越性。未来,团队后续将进一步优化电路架构,拓展电路规模,引入相似度计算等模块,推动Mamba模型在边缘AI设备中的实际部署与应用。