
8月11日消息,在世界机器人大会上,阿里达摩院宣布开源自研的 VLA 模型RynnVLA-001-7B、世界理解模型RynnEC、以及机器人上下文协议RynnRCP,推动数据、模型和机器人的兼容适配,打通具身智能开发全流程。
具身智能领域飞速发展,但仍面临开发流程碎片化,数据、模型与机器人本体适配难等重大挑战。达摩院将MCP(Model Context Protocol)理念引入具身智能,首次提出并开源了RCP(Robotics Context Protocol)协议以推动不同的数据、模型与本体之间的对接适配。达摩院打造了名为RynnRCP的一套完整的机器人服务协议和框架,能够打通从传感器数据采集、模型推理到机器人动作执行的完整工作流,帮助用户根据自身场景轻松适配。RynnRCP现已经支持Pi0、GR00T N1.5等多款热门模型以及SO-100、SO-101等多种机械臂,正持续拓展。
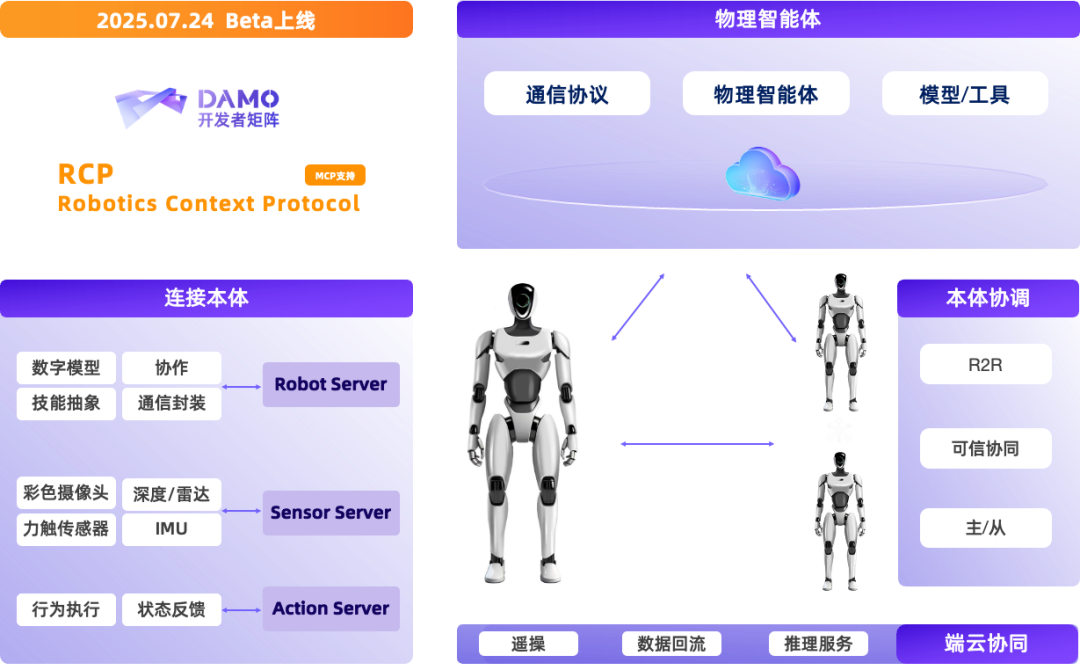
具体而言,RynnRCP包括RCP框架和RobotMotion两个主要模块。RCP框架旨在建立机器人本体与传感器的连接,提供标准化能力接口,并实现不同的传输层和模型服务之间的兼容。RobotMotion则是具身大模型与机器人本体控制之间的桥梁,能将离散的低频推理命令实时转换为高频的连续控制信号,实现平滑、符合物理约束的机器人运动。同时,RobotMotion还提供了一体化仿真-真机控制工具,帮助开发者快速上手,支持任务规控、仿真同步、数据采集与回放、轨迹可视化等功能,降低策略迁移难度。
大会上,达摩院还宣布开源两款具身智能大模型。RynnVLA-001是达摩院自主研发的基于视频生成和人体轨迹预训练的视觉-语言-动作模型,其特点是能够从第一人称视角的视频中学习人类的操作技能,隐式迁移到机器人手臂的操控上,从而让机械臂操控更加连贯、平滑,更接近于人类动作。
世界理解模型RynnEC将多模态大语言模型引入具身世界,赋予了大模型理解物理世界的能力。该模型能够从位置、功能、数量等11个维度全面解析场景中的物体,并在复杂的室内环境中精准定位和分割目标物体。无需3D模型,该模型仅靠视频序列就能建立连续的空间感知,还支持灵活交互。
此外,达摩院还在上月开源了WorldVLA模型,首次将世界模型与动作模型融合,提升了图像与动作的理解与生成能力。相比传统模型,该模型抓取成功率提高4%,视频生成质量显著改善,展现了较好的协同性和准确性。
开源链接:
·机器人上下文协议RynnRCP
https://github.com/alibaba-damo-academy/RynnRCP
·视觉-语言-动作模型 RynnVLA-001
https://github.com/alibaba-damo-academy/RynnVLA-001
·世界理解模型 RynnEC
https://github.com/alibaba-damo-academy/RynnEC
·WorldVLA模型








