

近年来,随着AI应用场景的爆发式增长,AI算法对算力的需求急剧上升,传统的冯・诺依曼架构以计算为核心,处理器与存储器之间的物理分离导致大规模数据频繁迁移,进一步限制了AI芯片的整体性能,难以满足AI应用对于低时延、高能效以及高可扩展性的迫切需求。而存算一体技术,正在成为解决这些问题的关键。
一方面,学术研究领域,存算一体技术的相关成果不断涌现,另一方面,产业界也在积极推动存算一体芯片的落地,其价值被越来越清晰地认知和挖掘。
在今年的WAIC上,国内领先的存算一体芯片厂商后摩智能发布了国内首颗面向端边大模型的存算一体AI芯片——后摩漫界M50,以行业最高能效比引发关注。
WAIC举办期间,后摩智能创始人吴强博士接受了媒体采访,分享了过去几年来在技术研发、战略等方面的进展,并就M50技术创新亮点进行了介绍。
锚定端边大模型AI计算赛道
后摩智能成立于2020年年底,专注于端侧AI芯片的研发,利用存算一体传统技术架构打造高能效低功耗AI芯片。
四年前后摩智能成立时,存算一体赛道国内鲜有相关的企业,该技术在行业中也很少被主流公司提及,并未受到广泛关注。选择这条赛道,吴强称一方面与求学期间的高能效比计算芯片研究方向一致,AI时代解决功耗墙和存储墙的问题,存算一体是必须走的一条路径。另一方面,中国芯片企业参与全球竞争,实现弯道超车,需要有创新架构,才可能另辟蹊径。
和众多高科技初创公司一样,后摩智能也经历过创业初期的阵痛。尽管2022年摩智能便推出首款面向智能驾驶领域的存算一体大算力芯片,但由于产品性能和成本与市场需求产生错配,并未一炮打响。
随后,后摩智能调整策略和定位,聚焦于端边侧AI,致力于成为端边大模型AI芯片的领跑者。
吴强表示,过去两年,行业最大的变化是大模型,后摩智能团队也投入大量时间进行大模型时代计算需求和行业应用的研究。
“大模型在AI应用中既要计算密集,又要计算带宽面积,而存算一体本身解决的问题也正是如此,因此从2023年开始,特别是针对大模型与存算一体的结合,后摩团队投入很多资源研究架构、设计,包括量化等方面。”吴强说。

两年来,围绕上述研究内容,后摩智能在ISCA/ISSCC等国际顶会上陆续发表了30余篇学术论文。今年7月,与北京大学团队合作的“面向边缘侧的H2-LLM推理加速架构”论文,在计算架构国际顶会ISCA上获得年度最佳论文奖。
在吴强看来,大模型在整个产品的底层逻辑上,跟互联网时代的产品显著不同,更加快速,直接的创造生产力,可以在很快的时间内变成超级应用。同时,因为处理的数据量大,大模型更依赖于算力,对计算效率的依赖非常大。
吴强认为,未来大模型发展有两个重要趋势方向:一是大模型的重心逐渐从训练向推理迁移。二是从云端智能向边缘侧端侧发展,形成端边和云端的协同。90%的数据处理可能在端边,只有10%的复杂任务在云端完成。端边AI有很多先天优势,比如更好的实时响应,更低的成本,更安全的数据隐私以及更好的个人用户体验等。
“存算一体技术的原生优势,适合以计算为核心,且对带宽要求极高的场景,后摩智能对AI计算场景有深刻的理解与技术积累。正因如此,我们聚焦端侧大模型的AI计算,希望能够让存算一体和大模型形成共振,释放出更大势能。”吴强说。
最高能效比端边大模型AI芯片如何打造?
在今年的世界人工智能大会期间,摩智能正式发布全新端边大模型AI芯片——后摩漫界M50。经过两年潜心研发,后摩智能后交出首份亮眼答卷。
M50芯片实现了160TOPS@INT8、100TFLOPS@bFP16的物理算力,搭配最大48GB内存与153.6 GB/s的超高带宽,典型功耗仅10W。是目前市场上能效比最高的端边大模型AI芯片,和传统架构相比,M50的能效提升5~10倍。M50预计今年Q4量产交付。
M50的技术创新突破还包括:
M50采用第二代SRAM-CIM双端口存算架构,实现权重加载和矩阵计算同时进行;
灵活的存算分离可测性设计,测试覆盖率超过99%;
支持多精度混合运算,可兼顾模型部署的各项需求;
双电源轨设计,大幅缓解PI风险。
在边端场景下,实现高算力、高带宽和低功耗的兼顾并不容易。之所以取得这样的成绩,吴强表示,一方面主要在于多年来后摩智能在存算IP方面的技术创新和积累。另一方面,是在IPU层面的不断打磨和完善。
吴强进一步介绍,M50采用的是后摩智能对外发布的第二代存算一体IP。通过多项创新,实现效率的显著提升,其中包括很多自研创新技术突破。包括双端口加载和计算定型以及量产,全自研CBIST和MBIST检测与修复等,保持电源稳定性等,很多都是没有既往经验的基础上逐步探索而来,后摩智能也申请了多项专利。

而如何高效使用IP,则考验AI处理器或者是IPU的设计能力。在M50中,后摩智能也引入了自研二代IPU的架构设计——天璇。天璇面向边端AI大模型应用,进行了特定优化,具备更灵活的扩展性,对大模型更友好。
通过压缩自适应计算周期实现弹性计算(Elastic Computing),天璇最高可提供160%的加速效果。通过内建的高速多芯互联技术,可实现算力与带宽扩展。
此外,天璇架构的另一个优势在于,除特殊场景需要额外量化外,浮点模型无需先量化再计算,可直接运行,提升应用效率。
“在存算架构上直接进行浮点计算,并实现芯片量产,后摩智能应该是行业首个,通过这个架构优化,能够大大加快应用落地的速度。”吴强表示。

在软件方面,M50搭配后摩智能推出新一代编译器——后摩大道,基于底层编译架构重构,非常灵活易用,支持主流深度学习架构,同时尽可能兼容CUDA Runtime。同时,可根据芯片架构自动选择最优算子,无需开发者手动尝试。此外,后摩大道提供原生浮点算力支持,无需量化参数和精度调优。
拓展产品组合 使能边端大模型应用场景
除了M50之外,此次后摩智能还发布了基于M50的系列配套产品,包括面向终端的力擎系列M.2卡,针对边缘侧的力谋加速卡系列,以及计算盒子等硬件组合,形成覆盖移动终端与边缘场景的完整产品矩阵。

其中,力擎LQ50 M.2卡拥有只有一口香糖大小的小巧尺寸,但性能强悍,具有160TOPS的算力,单芯片支持7B/8B模型推理超25tokens/s,最高支持48GB内存,功耗仅13瓦,为AI PC、AI Stick、陪伴机器人等移动终端提供 "即插即用" 的端侧AI能力。而双芯形态力擎LQ50 DUO M.2卡具有320TOPS算力,最高支持96GB存储,能够有效支持多模态百亿参数模型在端边运行。
而对于边缘场景,力谋LM5050加速卡、力谋LM5070加速卡则拥有半高半长、全高全长尺寸。分别集成2颗和4颗M50,提供从320TOPS到640TOPS算力的支持,支持70B-140B参数模型。
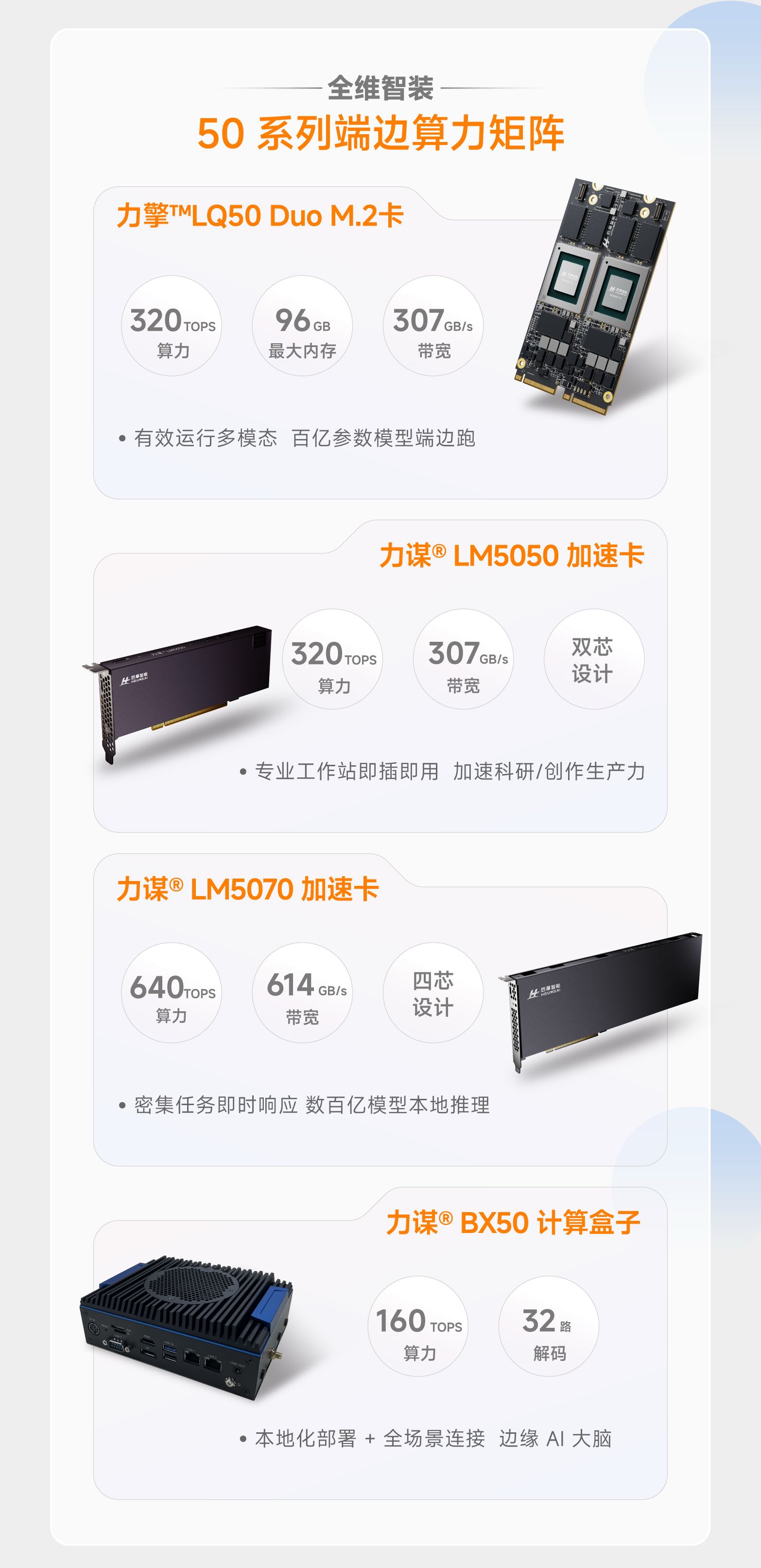
此外,边缘侧新品还包括BX50智能计算盒,具有丰富的接口,并且支持安全加密等功能,适用于信创市场等领域。
“希望通过采用原方案+AI的模式,使能边端大模型的应用场景。通过适配Arm,X86、LInux等不同架构,以及Widnows、麒麟等操作系统,形成一个可以满足多元化需求的产品和解决方案。”吴强说。
据了解,M50属于需求驱动,关键指标都是由后摩智能以及头部客户共同定义,对于场景落地更加具有针对性。产品推出后受到市场的关注,目前意向客户包括联想、讯飞听见、中国移动等。
据吴强介绍,后摩智能的端边大模型AI芯片以及相关产品,可以广泛应用在Pad/PC、智能语音设备、陪伴机器人、车载大模型域控、AI Stick拓展坞、计算盒子、边缘计算一体机等场景,助力消费终端、智能办公和智能工业等领域的产业升级。
会上,后摩智能还进行了M50相关产品在一些应用场景方面的演示。
一是基于千问3-14B模型的知识问答应用。二是会议纪要,基于千问3-8B的模型,能够识别不同发言人的内容,一个小时会议在5-6分钟完成会议纪要、待办事项等的生成。三是公文写作,在完全国产信创系统的基础上,运行千问2.5-7B模型。
围绕上述场景,吴强表示,主要是围绕大模型对于生产力带来的变革,目前比较看重Pad和PC、智能语音设备等方面的应用。此外,尽管具身智能目前还处于早期,但作为新兴赛道代表着未来的方向,后摩智能愿意为其提前布局。

启动下一代DRAM-PIM技术研发 首颗芯片有望明年问世
成立至今,存算一体技术一直是后摩智能的立身之本。在保持技术理念的同时,后摩智能也不断地去构建更加完整的计算技术体系。
据吴强透露,一年前,后摩智能逐渐从SRAM CIM存内计算技术向Dram PIM技术拓展,使计算与存储的协同更加紧密高效,并进行全方位的布局。
据集微网了解,DRAM PIM有两种技术架构,一种是On-Die PIM,在DRAM DIe内部直接布局计算单元,通常需要重构存储阵列和外围电路。一种是通过3D封装技术,将独立的逻辑层与FRAM层堆叠,计算单元位于逻辑层。两种方式对应不同的成本和性能,适合不同的应用场景。
而通过将计算单元直接嵌入DRAM阵列的方式(On-Die PIM),将突破1TB/s片内带宽,能效较现有水平再提升三倍,推动百亿参数大模型在终端设备实现普及,让更强大的AI算力能够融入PC、平板等日常设备。
吴强称明年Q3左右,后摩智能基于DRAM PIM技术的首颗芯片产品将有望问世。
在完善技术布局的同时,近年来后摩智能也得到稳健发展。自2022年起,后摩智能相继完成PreA、A和A+三轮融资,主要投资方包括联想创投、君海创新、中移资本等。近期,后摩智能获得了北京国有资本,亦庄国投等机构的资本支持,也表明了其技术发展方向和愿景得到了重量级产业方和国有资本的认可。
吴强表示:“M50的发布只是一个开始,我们的目标是让大模型算力像电力一样随处可得、随取随用,真正走进每一条产线、每一台设备、每一个人的指尖。”








