
上海交通大学智能网联电动汽车创新中心团队在秦通、杨明老师指导下,于机器人领域顶级旗舰会议IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)上发表题为“Building Hybrid Omnidirectional Visual-Lidar Map for Visual-Only Localization”的研究论文。文章主要探讨了利用视觉和激光传感器构建具有纹理和几何信息的先验混合地图,为纯视觉机器人在困难环境下的定位导航提供了系统性解决方案。本文第一作者是溥渊未来技术学院访问学生黄竟洋。
研究背景
Research Background近年来,基于视觉的定位技术在机器人和自动驾驶等领域发挥着重要作用。然而,传统方法(如SLAM和SfM)存在深度估计不准确、计算成本高、环境适应性差等问题,尤其在纹理稀疏或动态场景中,单目或双目视觉的定位精度和鲁棒性受限。虽然激光雷达(LiDAR)能提供精确的3D结构信息,但纯LiDAR定位依赖高精度传感器,成本较高,且难以与视觉数据直接融合。现有的跨模态定位方法主要依赖几何对齐(如ICP)或深度学习,前者对点云质量敏感,后者计算开销大,难以在资源受限的平台上(如无人机)实时运行。因此,如何在低成本传感器组合(如相机+IMU)下实现高效、高精度的跨模态定位,仍是一个关键挑战。
研究成果
Research Results为了综合解决上述问题,本文提出一种混合视觉—LiDAR关键帧建图与纯视觉重定位框架,适用于计算资源受限的无人机。在建图阶段,系统融合四目相机图像与LiDAR数据,构建全向关键帧地图,精确关联图像特征与LiDAR点云深度,解决了传统视觉建图的尺度模糊和深度误差问题。在重定位阶段,系统先基于视觉特征检索相似关键帧,建立2D—2D匹配,再通过关键帧关联的3D点云实现2D—3D对应,最终结合PnP-RANSAC和位姿图优化计算精确位姿。
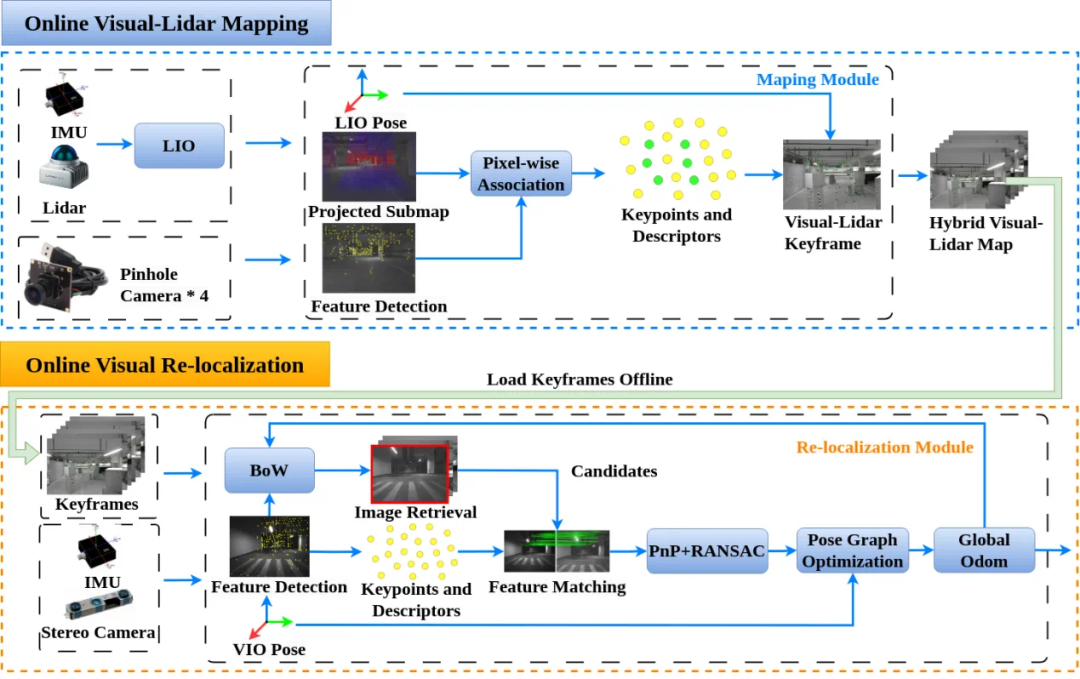
在线建图/定位算法框架图
该框架的创新点如下:
1)全向关键帧设计:利用多相机系统生成360°关键帧,支持任意视角的快速重定位,提升环境适应性。
2)轻量化跨模态融合:以关键帧为桥梁,高效关联视觉与LiDAR数据,避免传统ICP的高计算成本。
3)实时性优化:算法可在嵌入式设备上实时运行,适用于无人机自主导航。实验结果表明,该系统在复杂环境中的定位精度接近LiDAR,且计算效率满足实时性需求。
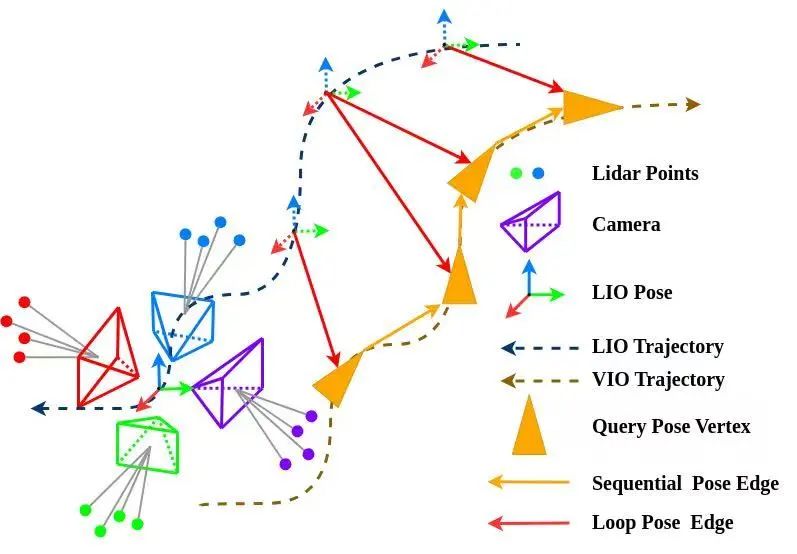
多方向节点位姿图优化示意图
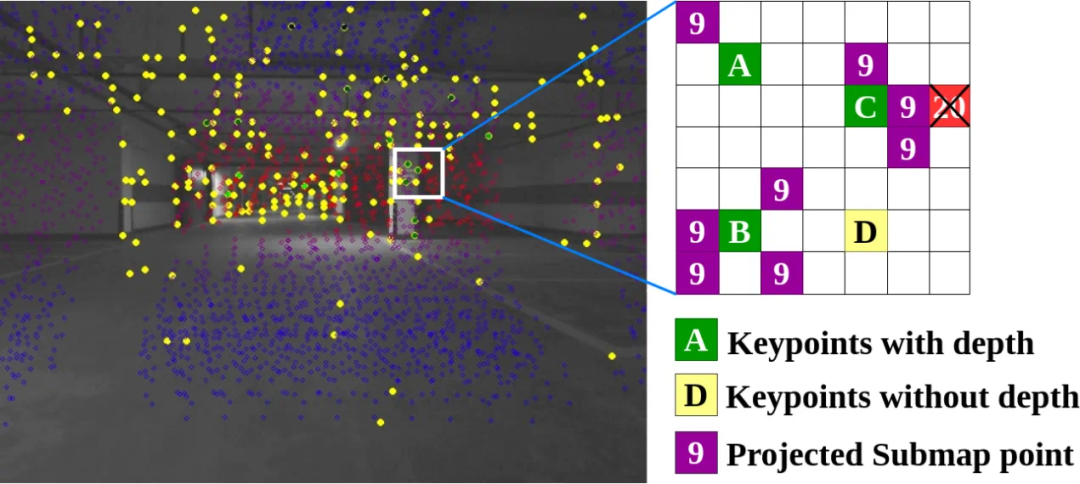
点云—像素关联方法








