
7月25日,WAIC 2025 前夕,后摩智能正式发布全新端边大模型 AI 芯片——后摩漫界®M50,同步推出力擎™系列 M.2卡、力谋®系列加速卡及计算盒子等硬件组合,形成覆盖移动终端与边缘场景的完整产品矩阵。M50 芯片实现了160TOPS@INT8、100TFLOPS@bFP16 的物理算力,搭配最大 48GB 内存与153.6 GB/s 的超高带宽,典型功耗仅 10W,相当于手机快充的功率,就能让PC、智能语音设备、机器人等智能移动终端高效运行1.5B 到 70B 参数的本地大模型,真正实现了"高算力、低功耗、即插即用"。

后摩智能创始人兼CEO吴强博士现场发布
当前大模型行业正经历深刻变革,ChatGPT 仅用 2 年便达成 Google 11 年积累的年搜索量规模,超级应用用户破亿的时间从手机时代的 16 年压缩至 ChatGPT 的 2 周。行业已进入"推理密度"与"能耗密度"双重敏感阶段,未来五年推理成本将占大模型全生命周期 80% 以上。在端边大模型部署"最后一公里"的竞争,或将成为决定未来产业格局的重要拐点。
高算力、高带宽、低功耗,这三项看似互斥的指标,正是存算一体技术大显身手的主场,后摩智能从 2020 年就开始深耕这一领域。存算一体通过把计算和存储单元集成在一起,让数据就近处理,从根本上解决了传统芯片“数据传输慢、功耗高”的问题。M50 芯片作为这项技术的集大成之作,其第二代SRAM-CIM双端口存算架构能让权重加载和矩阵计算同时进行,支持多精度混合运算,可兼顾模型部署的各项需求;后摩智能自主研发的第二代 IPU 架构——天璇,通过压缩自适应计算周期实现弹性计算(Elastic Computing),最高可提供 160% 的加速效果;通过内建的高速多芯互联技术,可实现算力与带宽扩展;同时适配后摩智能新一代编译器后摩大道®,可根据芯片架构自动选择最优算子,无需开发者手动尝试;支持浮点运算,无需量化参数和精度调优。和传统架构相比,M50 的能效提升 5~10 倍,完美适配了端边设备"算得快又吃得少"的需求。

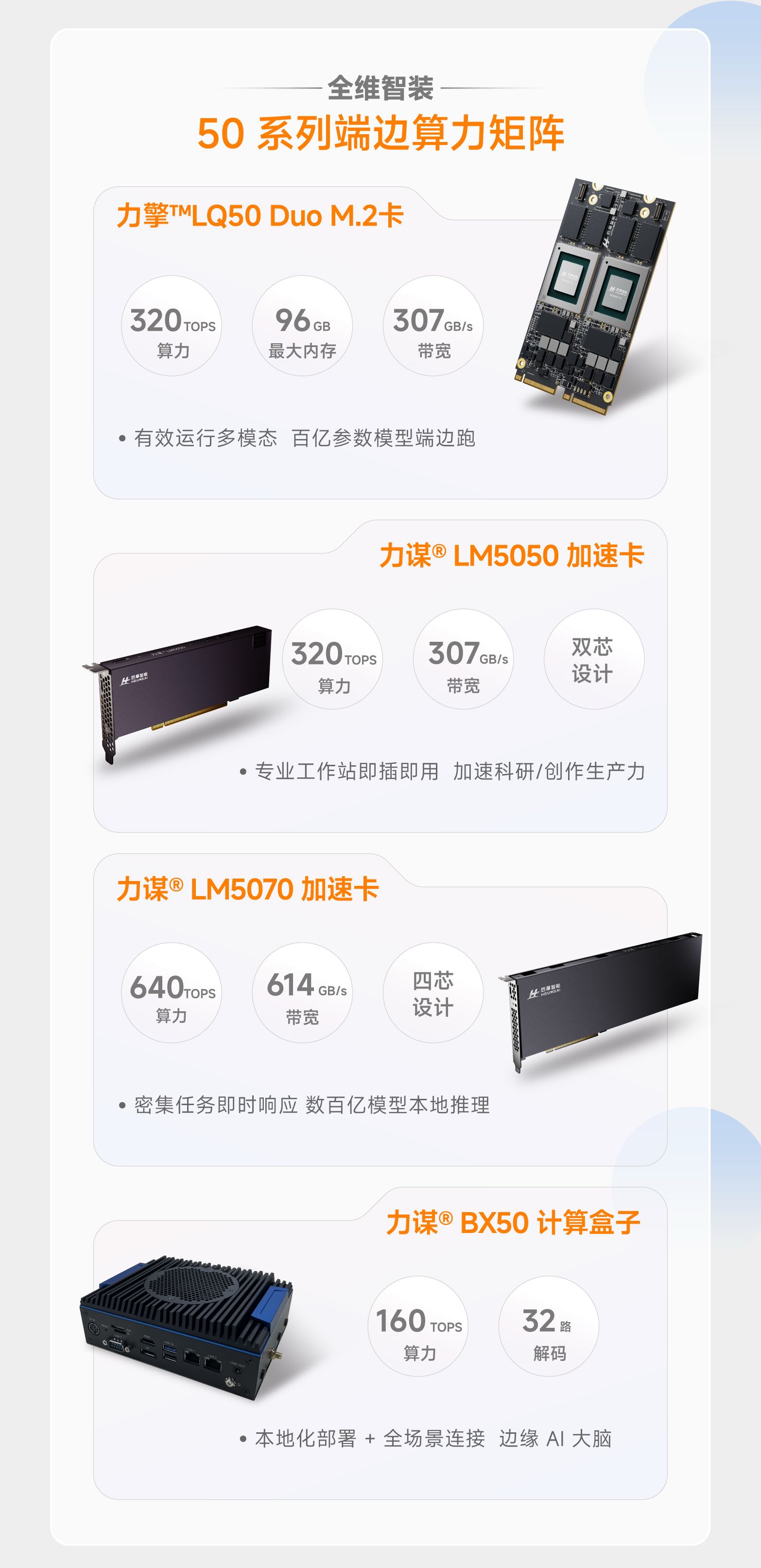
除了 M50 芯片,后摩智能此次发布的产品矩阵形成了覆盖端侧到边缘的多元算力方案。力擎™️LQ50 M.2 卡以口香糖大小的标准 M.2 规格,为 AI PC、AI Stick、陪伴机器人等移动终端提供 "即插即用" 的端侧 AI 能力,支持 7B/8B 模型推理超 25tokens/s;力擎™️LQ50 Duo M.2 卡集成双 M50 芯片,以 320TOPS 算力突破 14B/32B 大模型端侧部署瓶颈;力谋®LM5050 加速卡与力谋®LM5070 加速卡分别集成 2 颗、4 颗 M50 芯片,为单机及超大模型推理提供高密度算力,最高达 640TOPS;BX50 计算盒子则以紧凑机身适配边缘场景,支持 32 路视频分析与本地大模型运行。
这些产品可广泛应用于消费终端、智能办公、智能工业等多元领域,且均能在离线状态下实现全流程本地处理,从源头杜绝数据联网传输风险。例如在消费终端,赋能笔记本、平板电脑、学习机等设备本地大模型推理能力,无需联网即可完成智能交互、内容生成等任务,用户隐私数据全程闭环留存;智能办公场景中,智能会议系统在断网环境下仍能实现多语种翻译、纪要生成,会议内容不触云、不泄露;智能工业领域,产线质检与车路云协同通过本地算力完成实时分析决策,生产数据与运营信息在设备端闭环处理,避免云端传输隐患。后摩智能通过存算一体技术与大模型的深度融合,推动 AI 大模型在端边侧实现 “离线可用、数据留痕不外露”,构建起 “低功耗、高安全、好体验” 的端边智能新生态。
面向未来,后摩智能已启动下一代 DRAM-PIM 技术研发,通过将计算单元直接嵌入 DRAM 阵列,使计算与存储的协同更加紧密高效。该技术将突破 1TB/s 片内带宽,能效较现有水平再提升三倍,推动百亿参数大模型在终端设备实现普及,让更强大的 AI 算力能够融入 PC、平板等日常设备。
这样的技术方向和发展愿景也得到了重量级产业方和国有资本的认可,近两年以来,后摩智能已经获得了中国移动产业链发展基金、北京市人工智能基金,北京市亦庄产业升级基金、中国国有企业混改基金等多家机构的投资,为在端边大模型芯片领域的持续创新提供了有力支撑。后摩智能 CEO 吴强博士表示:“M50 的发布只是一个开始,我们的目标是让大模型算力像电力一样随处可得、随取随用,真正走进每一条产线、每一台设备、每一个人的指尖。”








