

7月16日,美国英伟达公司创始人兼首席执行官黄仁勋在第三届链博会开幕式上致辞表示,“中国的开源人工智能是全球进步的催化剂,使每个国家和行业都有机会参与AI变革”。不久前,其在接受央视新闻采访时宣布两个重要进展,美国已批准H20芯片销往中国,并同步推出了一款全新的、完全合规的中国特供版专业级RTX PRO GPU。
英伟达对华“合规芭蕾”经营策略
英伟达H20是专为符合美国特定出口管制要求而设计的A100/H100替代品。其核心性能,特别是FP64/FP32相较于A100/H100有显著降低,但通过配备高带宽HBM3显存并保留强大的NVLink互联能力,旨在维持在特定AI场景的竞争力。
今年4月,美国政府曾暂停向英伟达发放H20的出口许可证,导致公司面临超百亿美元的潜在损失。根据英伟达最新财年报告(截至2024年1月26日),中国市场为其贡献了170亿美元的营收,占总销售额的13%,是其实现增长的关键支柱。
据报道,英伟达已重新提交H20的销售申请,并获得了美国政府将发放许可证的保证,公司期望能尽快启动交付。
与此同时,英伟达CEO黄仁勋宣布推出全新的RTX PRO GPU。他将其定位为“智能工厂和物流领域数字孪生人工智能应用的理想选择”。据台媒《电子时报》披露,这款名为RTX PRO 6000D Blackwell的GPU将采用台积电4N定制工艺,搭载GDDR7显存,内存带宽高达1.1TB/s。这一规格使其在处理复杂数据和高负载任务时具备卓越性能,尤其适用于企业AI部署和AI工作站。
然而,英伟达在满足美国不断调整的出口限制方面仍面临挑战。有消息称,H20的替代版B30预计将于9月发售,其性能参数在现有基础上可能进一步受限。传闻其FP16算力约为80 TFLOPS出头,FP8接近200 TFLOPS出头,互连带宽约为1.5–1.6TB。从整体性能看,B30被认为基本不适合用于AI模型训练。相比之下,H20虽性能受限,但仍能通过优化内存方案、采用FP8精度及传统方法勉强用于训练。
事实上,英伟达的对华销售策略已演变为一场精密的 “合规芭蕾”,通过分层产品线布局实现精准卡位。H20作为专注训练及推理的定制芯片,凭借NVLink 4互联与HBM3显存支撑分布式计算;RTX PRO系列则聚焦专业可视化与轻量AI 设计,以GDDR7高带宽适配数字孪生场景;即将推出的B30芯片则剥离训练能力,纯推理定位进一步收缩功能边界。这种“功能切割术”既满足美方不断调整的出口限制条款,又通过差异化产品矩阵覆盖中国市场从高端训练到边缘推理的全场景需求,牢牢守住13%的全球营收基本盘。
在技术绑定层面,英伟达即使硬件性能受限,仍可在软件端通过CUDA工具链、NGC预训练模型库形成生态壁垒,仅PyTorch框架就包含超10万款基于CUDA 优化的模型,开发者迁移成本高达百万级代码量;硬件端则与浪潮、联想等中国服务器厂商深度定制联合方案,将单芯片销售转化为“芯片 + 整机 + 服务”的捆绑模式,既规避单卖芯片的政策风险,又通过系统级合作深化用户依赖。
芯片较量之外的生态对决
从行业发展的深层次看,美国政府也逐渐意识到,尽管对高端芯片实施出口管制,但中国在AI芯片领域的巨额投入正推动其加速填补算力缺口,寒武纪、壁仞等企业流片节奏提速,华为昇腾910B已进入多地智算中心采购清单,部分国产芯片在性能和应用层面已展现出与H20竞争的能力。
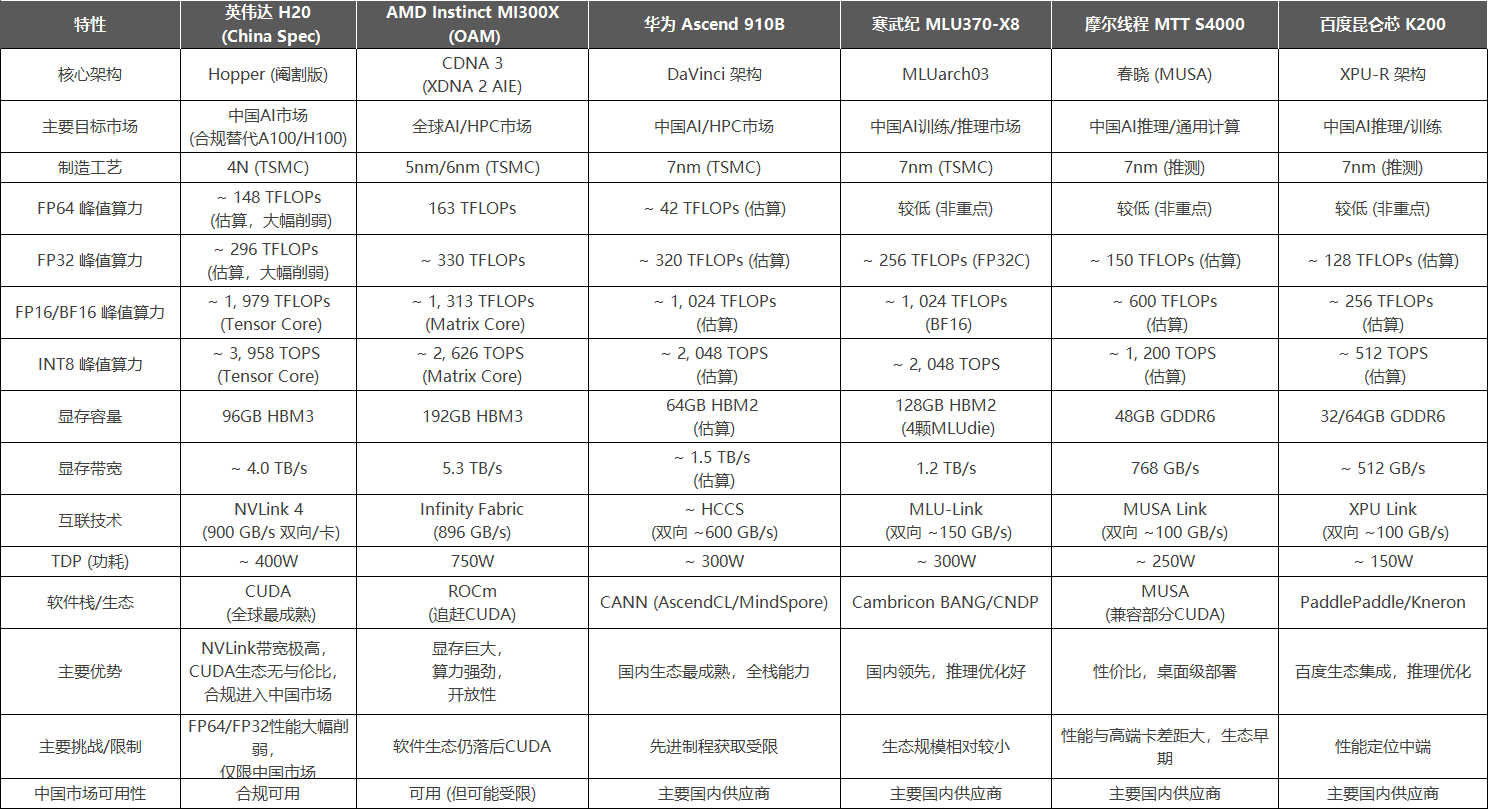
国外的相关GPU各有特点,H20作为特定地缘政治环境下的产物,最大优势在于保留了NVLink 4的超高互联带宽和大容量HBM3显存,这对于构建大规模AI集群进行分布式训练和推理至关重要,能部分弥补其核心计算单元性能(FP64/FP32)被大幅削弱的劣势,而CUDA 生态更是其护城河;AMD MI300X 纸面参数则非常亮眼,尤其是 192GB HBM3 显存是巨大优势,对处理大模型极其关键,不过 ROCm 生态是主要瓶颈,好在其正持续快速改善,同时该芯片功耗较高。
国内竞品方面,华为昇腾910B 目前国内综合实力最强的替代方案,拥有较高的FP32/FP16算力和较成熟的CANN软件栈(与MindSpore深度集成),以及华为的端到端解决方案能力,然而受制程限制,其HBM带宽相对国际旗舰有差距;寒武纪MLU370-X8 通过多芯粒集成实现高算力和大容量HBM2,在推理场景有较好表现和优化,但是MLU-Link互联带宽相对NVLink仍有较大差距;摩尔线程MTT S4000 / 百度昆仑芯 K200定位更偏向推理和中端训练市场,性能参数上与H20/MI300X/910B等旗舰卡差距明显,但在特定场景,如桌面级推理服务器、特定模型优化可能有成本和部署优势,生态处于早期发展阶段。
除了硬件参数,全球AI产业也深刻意识到,算力软件生态的成熟度远比单芯片参数更能决定技术落地的广度和深度,对于正加速追赶的中国算力产业而言,突破软件生态壁垒仍需攻坚三大关键节点。
首先,当国产芯片FP16算力达到320TFLOPS超越H20时,业界却发现大量开源AI框架仍默认调用CUDA内核。这种硬件领先却生态滞后的困境,折射出兼容性战役的核心价值,国产芯片要打破“能用但不好用”的魔咒,必须构建跨架构适配层。而兼容性攻坚的终极目标不是复刻CUDA,而是构建“一次开发、多端部署”的跨架构生态。目前中科院计算所研发的“异构计算中间件”已支持昇腾、寒武纪、AMD等8类芯片架构。
其次,CUDA的真正壁垒,在于全球200万开发者形成的创新网络。国产生态要实现从“技术可用”到“开发者拥护”的跨越,需要建立可持续的开发者激励机制。
最后,当美国商务部提出“让中国对美国技术上瘾”的策略时,国产算力生态更需警惕“表面兼容实则被卡脖子”的陷阱,真正的自主可控,体现在底层指令集到上层应用框架的全链条可控。
算力软件生态的攻坚战,本质是场没有硝烟的标准制定权之争。当国产芯片厂商不再纠结“如何兼容 CUDA”,而是思考“如何让全球开发者主动适配国产生态”时,才算真正突破了算力产业的致命短板。这场战役或许需要十年甚至更长时间,但每一行自主代码的积累,都在为中国算力产业铺设通往全球价值链顶端的阶梯。







