
2025年7月9日,奎芯科技首款标准封装32Gbps UCIe IP解决方案成功通过硅验证,该方案在基板(substrate)上实现了25mm的长距离互连,并集成完整的控制器(Controller)与物理层(PHY)IP组合,为AI SoC客户提供高带宽、低延迟且灵活可靠的die-to-die(D2D)互联解决方案。

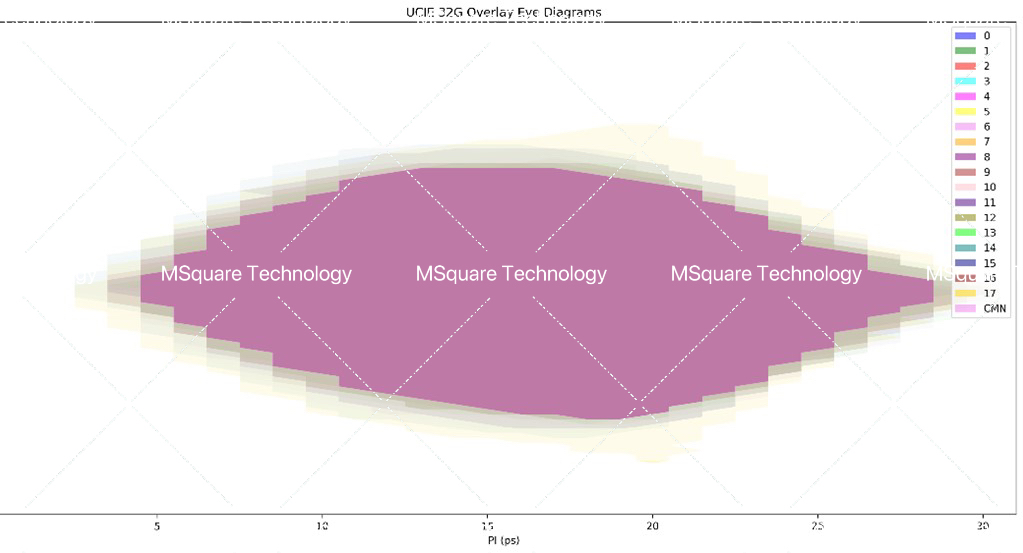
奎芯科技 32Gbps UCIe DATA0~15/VLD/TRK/CMN实测眼图
随着人工智能进入大模型时代,算力的边界正被不断突破。GPT-4、Gemini、Claude等多模态AI模型已迈入万亿参数量级,对芯片性能、内存带宽、系统结构都提出了前所未有的挑战。而真正拖慢AI系统效率的,不再是算力本身,而是芯片间的互联瓶颈。
Meta数据显示,约40%的数据中心运行时间浪费在数据等待和传输中,不是在“计算”,而是在“等数据”。在这样的背景下,芯片互连技术已成为影响AI算力效率的决定性因素。
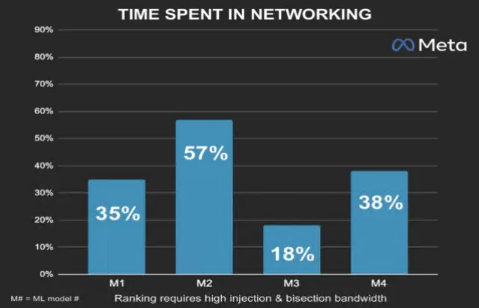
数据中心数据停留时间约 40% 被浪费在网络中(数据来源:Meta)
从大芯片到小芯片:Chiplet架构成为算力时代新共识
传统SoC(片上系统)集成方式,因光刻工艺极限和良率问题,已难以继续无限扩大芯片面积。随着先进工艺的成本上升,设计风险和开发周期也水涨船高。越来越多的芯片设计公司开始转向Chiplet架构 —— 将功能模块分拆为多个小芯片(Chiplet),通过高速互连集成成系统,既可复用已有IP,又能选择最优工艺节点进行布局优化。
这一变化带来了新的技术核心:“如何在Chiplet之间实现低延迟、高带宽、低功耗、可标准化的互连?”
UCIe:下一代AI SoC的互连标准
Universal Chiplet Interconnect Express(UCIe)作为开放的芯粒互连协议,由Intel主导,并获得TSMC、Samsung、AMD、Google等主流芯片大厂支持,正在成为AI芯片时代最主流的Die-to-Die互连标准。
UCIe的优势在于其开放生态、封装适应性强、易于集成,为不同芯粒之间的高效互连提供了统一接口,显著降低异构集成的技术门槛,助力产业协作与供应链标准化。同时,UCIe兼容多种封装形式,适用于从先进封装到标准基板的多样系统设计,在功耗、成本与系统灵活性之间提供了良好平衡。
对比NVIDIA的NVLink、自研高速定制互连等封闭协议,UCIe代表的是未来“去中心化+异厂协同”的互连范式。
奎芯科技:业界领先的UCIe接口IP解决方案
面对这一产业变革,奎芯科技率先推出面向AI/HPC应用场景优化的UCIe IP解决方案,不仅遵循标准协议规范,更结合实际需求,在传输性能、封装适配和客户易集成方面做出系统性提升。奎芯科技UCIe关键优势如下:
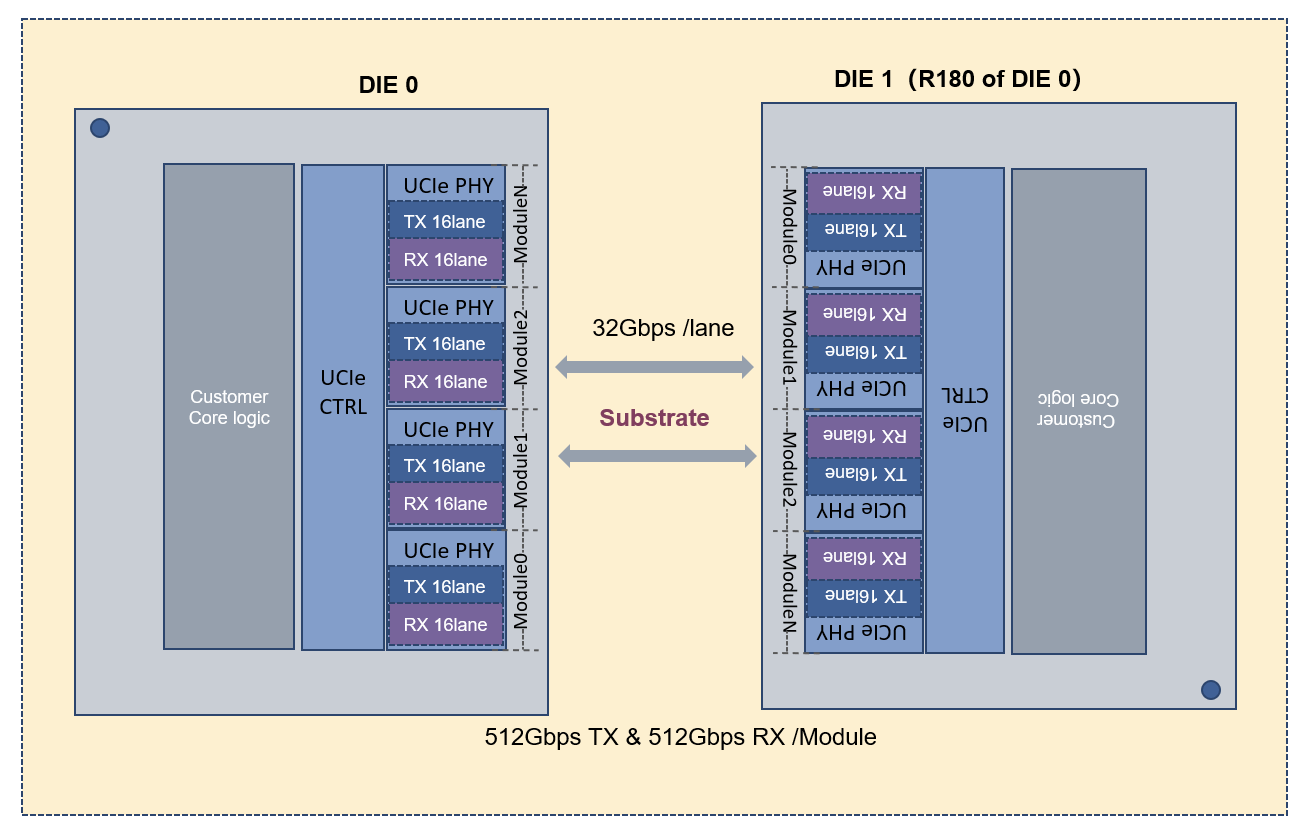
1. 32Gbps单通道速率,面向未来AI集群带宽需求
- 支持大模型推理和训练中的高频交互;
- 在实际部署中可支撑 >1Tbps 多通道聚合带宽;
2. 25mm互连距离,拓展Chiplet布局空间
- 满足主流封装设计中的跨芯粒传输需求;
- 适用于非对称芯片形态,灵活适配大型SoC架构规划;
3. 兼容标准基板封装,降低系统复杂度与成本
- 无需2.5D/3D封装,有效规避中介层(interposer)等复杂结构设计带来的挑战
- 提升制造良率与供应链灵活性,适合量产化导入;
4. Controller + PHY完整IP组合,一站式集成
- 节省客户开发资源,避免多家IP适配带来的接口不兼容风险;
5. 提供Controller+PHY整体harden服务,同时提供仿真模型参考验证环境,降低集成复杂度,缩短客户设计周期。高可靠性信号完整性/电源完整性设计与验证
- 全链路 SI/PI sign-off,仿真结果与硅验证结果一致性高
- 提供参考封装设计及SI/PI评审,支持客户实现从设计到封装的高可靠性解决方案
当前该方案已在多个AI SoC客户项目的Die-to-Die互连场景完成部署,同时正与多家新客户进行前期合作洽谈。
连接,正在成为AI芯片的“核心IP”
过去十年,业界关注的是AI算力本身;未来十年,“如何连接AI算力”将成为竞争焦点。奎芯科技以UCIe为起点,正构建全栈互连能力,为AI、HPC、边缘计算等复杂应用场景,提供可靠、可扩展、可落地的芯片互连IP解决方案。









