
DAC (Design Automation Conference),全称国际设计自动化会议, 由美国计算机协会(ACM)和电气与电子工程师协会(IEEE)联合主办,始于1964年,拥有超过60年的历史,是全球芯片设计与自动化领域规模宏大、影响深远、历史悠久的顶级会议之一。
华中电子科技大学集成电路学院缪向水、李祎教授团队在近日于美国旧金山召开的第62届DAC会议上报告了基于阻变存储器的存算一体技术最新研究成果“ReSMiPS: A ReRAM-based Sparse Mixed-precision Solver with Fast Reordering Algorithm”。该工作为稀疏矩阵方程求解这一重要基础问题,提供了一种高能效、高精度的存算一体求解架构。我院2023级博士生付雨阳,2019级博士生李健聪(已毕业,现于香港科技大学从事博士后研究)为论文共同第一作者,李祎教授和香港智能晶片与系统研发中心陈佳博士为论文共同通讯作者。华中科技大学是论文第一完成单位。
稀疏矩阵方程(Ax=b)求解是科学计算、具身智能等领域的基础数学问题。基于CPU和GPU的传统数字求解器在执行大规模稀疏矩阵方程求解时,由于“存-算”分离的冯·诺依曼计算架构,面临着严重的访存瓶颈,难以满足高效求解需求。尽管基于阻变存储器(ReRAM)的存算一体技术为高效的矩阵计算提供了一种潜在硬件架构,但是,一方面存储器的交叉阵列结构仅适配稠密矩阵计算,在部署稀疏矩阵时,大量0元素不可避免的会导致算力的浪费。另一方面,存算一体架构通常受制于模拟计算机制,难以满足稀疏矩阵方程的双浮点精度(FP64)求解需求。
针对上述问题,研究团队构建了一套基于ReRAM的混合精度异构存算一体求解架构ReSMiPS,以实现稀疏矩阵方程的高效、高精度求解,取得了以下进展:
在矩阵部署层面,针对稀疏矩阵在ReRAM阵列上的高效部署难题,提出了一种快速稀疏矩阵排序算法(Fast Sparse Matrix Reordering Algorithm,FSMR)。FSMR算法通过对称化变换矩阵并兼顾带宽压缩特性,相较Cuthill-Mckee等现有重排算法,可以实现非零元素的高效聚簇,显著提升阵列利用率,突破稀疏矩阵乘法在阵列中的计算并行度限制(图1(a))。
在数据映射层面,针对FP64精度数据在ReRAM阵列中的存储和计算开销限制,提出了一种IF64数据映射格式,该数据格式兼顾了IEEE-754标准FP64格式的数据动态范围,同时通过约束尾数位宽,降低了硬件资源开销,结合所设计的浮点存算一体单元,可显著加速浮点稀疏矩阵计算(图1(b))。
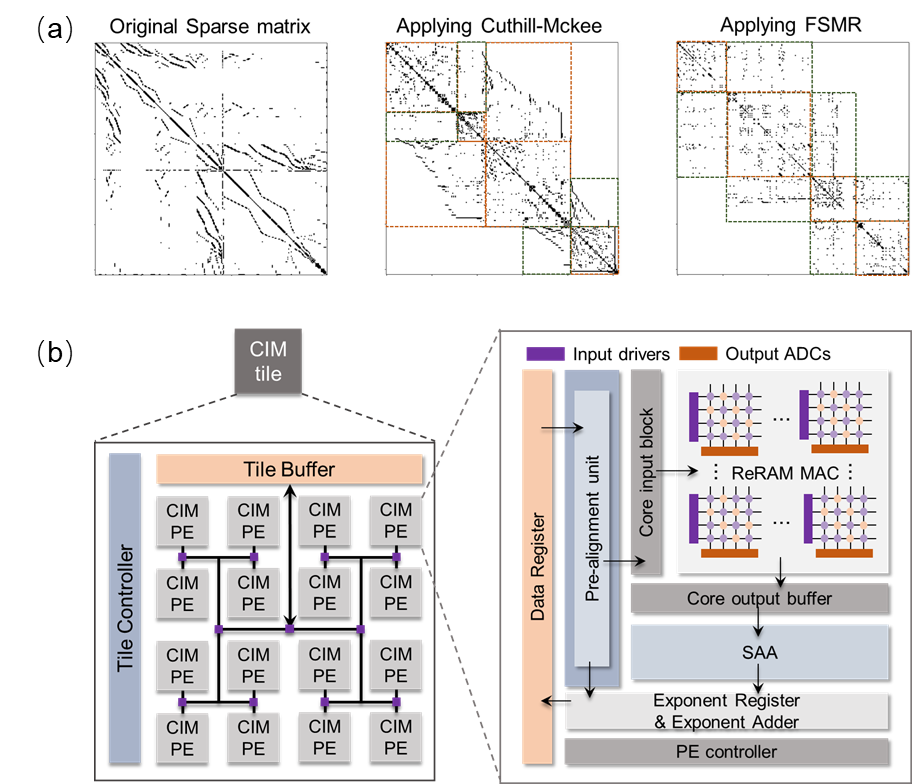
图1. (a)FSMR算法效果示意;
(b)基于ReRAM的浮点稀疏矩阵乘法架构
在架构层面,提出了结合IF64的ReRAM浮点矩阵乘法单元与FP64精度的数字处理单元的混合精度求解架构。通过ReRAM浮点计算单元加速近似求解,FP64数字单元实现误差修正的方式,在实现与CPU/GPU相当的数值求解精度的同时,降低大规模稀疏矩阵的迭代求解延时,提升求解能效(图2)。
使用SuiteSparse稀疏矩阵数据集的评估结果显示,ReSMiPS实现10-15的高精度求解时,计算速度相对 NIVIDA RTX 4070 Ti GPU提升约600倍,能耗降低至1/2100,且得益于FSMR算法对大规模稀疏矩阵条件数的约束,ReSMiPS在负载矩阵条件数达1018的恶劣收敛条件下,仍能实现稳定条件。该研究成果不仅突破了ReRAM存算一体技术在高精度稀疏矩阵方程求解中的应用瓶颈,也为未来芯片设计自动化、数字孪生等重要应用场景提供了可行的硬件加速方案。
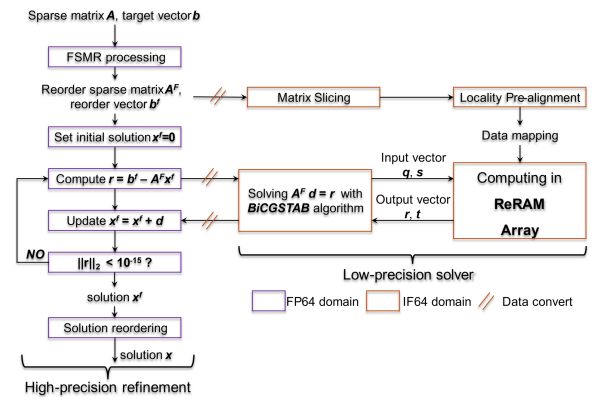
图2. 基于ReSMiPS系统的稀疏矩阵方程求解框架
本论文研究工作得到了国家科技创新2030重大研究计划(No. 2021ZD0201201)、国家重点研发计划(No. 2022YFB450010),湖北省杰出青年基金、华中科技大学基础研究支持计划等项目的资助,以及华中科技大学国家集成电路产教融合创新平台的支持。








