
在人工智能与集成电路技术深度融合的浪潮下,存算一体(CIM)架构因其高效能的数据处理能力成为突破传统计算瓶颈的关键路径。然而,面对大型语言模型(LLM)的复杂计算需求,现有CIM设计在精度、能效和离群值处理等方面仍面临显著挑战。同时,神经网络硬件的片上训练与微调功能也对存算一体技术提出了更高的要求。针对这些核心问题,复旦大学集成芯片与系统全国重点实验室刘琦/陈迟晓课题组近期研制了两款存算一体AI芯片:LLM离群值适配的混合精度存算一体芯片OA-CIM和支持片上微调/训练的RRAM/SRAM协同存算一体芯片Hairuo。两项科研成果近期发表于国际固态电路权威期刊 IEEE Journal of Solid-State Circuits (JSSC),论文第一作者分别为何斯琪(博士生)、朱浩哲(青年研究员)和穆琛(博士生)。
1、OA-CIM:LLM离群值适配的混合精度存算一体芯片
随着大模型参数规模的急剧增长,其通信和计算开销大幅增加,对处理器的能效和内存占用提出了严峻挑战。存算一体(CIM)架构通过将计算逻辑直接集成到存储单元中,有效缓解了数据搬运带来的带宽限制,成为提升能效的潜在解决方案。但现有的CIM设计在应用于LLMs时,仍面临精度与内存需求之间的权衡问题,尤其是对权重中普遍存在的离群值(outliers)的高效处理能力不足。
针对这一挑战,全国重研究团队研制了OA-CIM,一款支持浮点/定点混合精度计算的存算一体芯片。该芯片结合了离群值感知量化技术与浮点/整数兼容的存内计算架构,实现了BF16离群值与INT4常规值的高效能效混合处理。相关成果以“A 22-nm 109.3-to-249.5-TFLOPS/W Outlier-Aware Floating-Point SRAM Compute-in-Memory Macro for Large Language Models”为题,被集成电路设计领域顶级期刊IEEE Journal of Solid-State Circuits (JSSC)录用。论文链接:https://ieeexplore.ieee.org/document/11016687。
OA-CIM原型芯片基于22nm工艺设计并流片,片上集成了512KB SRAM存算一体阵列。该工作的主要亮点包括:
提出了一种支持混合精度(BF16/INT4)的SRAM存算一体架构,通过创新的离群值感知量化技术和浮点/整数兼容的乘法累加电路,在保证模型精度的同时实现了高能效计算,峰值能效达到249.5 TFLOPS/W;
开发了XOR共享的非最大指数门控方案,通过共享XOR逻辑单元优化浮点数据流中的指数比较和减法操作,将指数处理单元的延迟降低1.54倍,面积效率提升1.43倍;
提出了分布偏移权重编码技术,利用LLM权重的统计特性优化位线充放电过程,结合动态范围驱动的预充电门控,使读操作功耗降低1.67倍。
芯片测试表明,OA-CIM在运行OPT-6.7B/13B等大型语言模型推理任务时,与全精度BF16基线相比仅增加0.5%的困惑度(perplexity),同时系统峰值能效达到109.3-249.5 TFLOPS/W,较现有混合精度存算一体设计提升2.7-3.1倍。
集成芯片与系统国家重点实验室、复旦大学集成电路与微纳电子创新学院为上述论文的第一完成单位,何斯琪博士生和朱浩哲青年研究员为共同第一作者,朱浩哲和陈迟晓副研究员为共同通讯作者。该工作得到了国家自然科学基金(62304047、62488101)和鹏城-中移动科技创新基金2024ZY2B0070的资助。

OA-CIM芯片的版图照片
2、支持片上微调/训练的RRAM/SRAM协同存算一体芯片
在许多端侧场景下,神经网络计算硬件需要对于新的任务具备学习、适应能力,即支持片上训练/微调功能。相比于推理,片上微调需要更多的数据传递和计算开销,对于计算硬件提出了更高的需求。CIM技术通过紧密集成存储和计算,减少了数据移动的延迟和能耗。其中,高密度、高能效RRAM存算一体技术为大规模低功耗边缘计算提供了更多机会。然而RRAM存在有限耐久性,写开销等问题,当前RRAM CIM芯片主要侧重于神经网络推理,很少涉及片上训练或微调。
针对这一挑战,全国重研究团队研制了Hairuo,一款支持片上微调/训练的RRAM/SRAM协同存算一体芯片。该芯片通过比特级细粒度优化,实现了兼容主流CNN/Transformer网络的边缘高效微调,单次微调过程仅需对RRAM进行不超过10次写翻转。相关成果以“A 28-nm RRAM/SRAM Collaborative CIM Accelerator Supporting RRAM-Endurance-Latency Awareness for Edge Fine-Tuning”为题,被集成电路设计领域顶级期刊IEEE Journal of Solid-State Circuits (JSSC)录用。论文链接:https://ieeexplore.ieee.org/document/11037778。
Hairuo原型芯片基于28nm工艺设计并流片,片上集成了144KB RRAM存算一体阵列和32KB SRAM存算一体阵列。该工作的主要亮点包括:
提出了一种RRAM-MSB-SRAM-LSB(RMSL)比特级协同存算一体宏单元。通过协同部署高精度微调权重和低精度推理权重,减少了RRAM单元的翻转次数,缓解了RRAM的耐久性问题,同时实现了高达76.25 TOPS/W的峰值能效;
提出了RRAM-Sparse-SRAM-Dense(RSSD)权重更新引擎。利用权重更新过程中的位翻转差异,最大限度地减少了与 RRAM访问相关的长读写延迟,使超过95%的RRAM访问稀疏化。此外对于RRAM的访问延时,在推理阶段,通过流水线权重静止数据流实现了对于RRAM读出延时的消除,实现了更高的系统吞吐率;
提出了基于softmax归一化共享的噪声注入(SOSNI)机制,实现了低权重更新硬件开销。通过对权重梯度量化注入噪声进行近似计算,减少了计算延迟并提高了模型量化的鲁棒性。
芯片测试表明,Hairuo芯片在ResNet18及ViT-Base网络权值微调过程中,所需RRAM更新不超过10次,存算一体宏单元和系统能效分别为76.25 TOPS/W和22.07 TOPS/W。所提出的RRAM数字存算一体SoC实现了高达143倍RRAM耐久性提高、117倍和144倍RRAM写入能耗(0.047 mJ)和延迟(0.047 ms)降低。
集成芯片与系统国家重点实验室、复旦大学集成电路与微纳电子学院为上述论文的第一完成单位,穆琛博士生为论文第一作者,刘琦教授与陈迟晓副研究员为共同通讯作者。该工作得到了国家自然科学基金(62495101)、上海市2024 年“科技创新行动计划”集成电路基础研究项目(24JD1400300)以及鹏城-中移动科技创新基金项目(2024ZY2B0070)的资助。
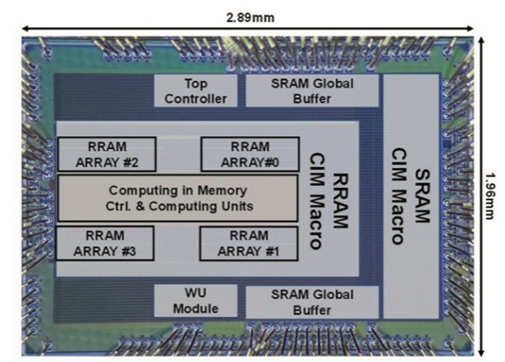
Hairuo芯片的版图照片









