6月20日,华中科技大学集成电路学院缪向水、李祎教授团队与清华大学集成电路学院钱鹤、吴华强教授团队于Science Advances(《科学进展》)合作发表了忆阻存算一体技术的最新研究成果“Memristive floating-point Fourier neural operator network for efficient scientific modeling”。该论文报道了国际上首个基于忆阻器的浮点精度神经网络求解系统,实现了高精度、高能效、低延时的智能科学计算。
科学计算建模是现代科学研究与工程设计中的重要基础问题。随着传统数值求解器在复杂建模问题中(如非线性微分方程模型)的求解延时难以满足需求,以傅里叶神经算子(Fourier Neural Operator,FNO)为代表神经网络求解器开始受到广泛关注。神经网络求解器的训练与部署依赖高能效、大算力的先进计算平台。基于忆阻器的存算一体芯片与系统为突破冯·诺依曼瓶颈,实现神经网络的高效训推提供了一种有潜力的解决方案。然而,与分类、识别等端侧神经网络应用不同的是,FNO等神经网络求解器的训推通常需要单浮点计算(FP32)精度以满足求解需求。忆阻阵列的模拟计算精度限制、器件实现高精度“写-验证”编程的时间与功耗开销等因素进而成为制约实现浮点精度神经网络求解器训推的关键瓶颈。
针对上述问题,我校研究团队在前期忆阻高精度科学计算系统(Sci. Adv. 2023, Sci. Adv 2025, IEDM 2024)研究基础上,与清华大学团队合作构建了一套基于忆阻器的浮点精度神经网络求解系统,实现了FNO网络的高精度训练与高效推理。合作团队对算法、系统与电路进行全层次协同优化设计:电路层面,提出了混合二值忆阻单元与多值忆阻单元的浮点矩阵乘法电路,通过调控浮点数据的片上映射构成,满足不同求解任务的能效与精度需求;系统层面,构建了“通用数字处理单元-专用数字处理单元-忆阻存算一体单元”的超异构计算系统,在训练阶段启用通用数字处理单元配合忆阻器芯片实现高精度训练,在推理阶段则启用专用数字处理单元实现高能效推理;算法层面,利用FNO网络“动态权重+固定权重”的构成特性,在训练中进行灵活部署,提高训练准确率的同时,降低系统功耗开销。
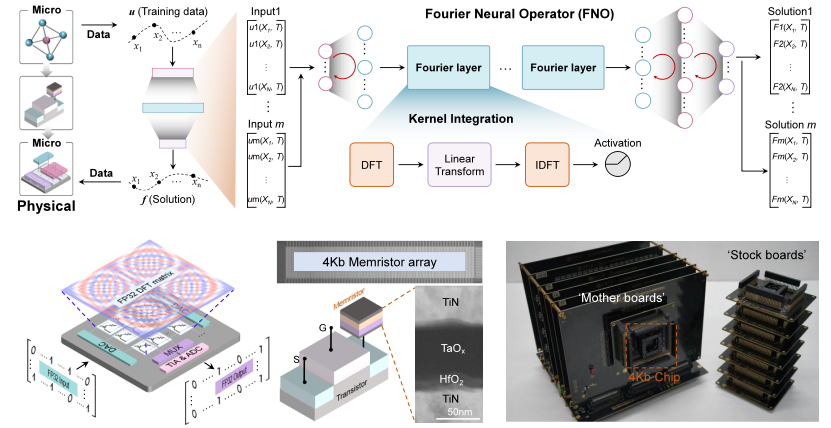
图1. FNO网络与忆阻存算一体硬件系统
合作研究团队在180 nm忆阻器芯片测试系统(集成了8块4 Kb忆阻器芯片)上完成了1-D和3-D FNO网络的训练与部署实测(图1)。针对基于1-D网络的Burger’s方程求解任务,忆阻计算系统实现了99.6%的求解准确率,相对FP32精度的数字计算系统,精度损失仅0.2%,推理能效提升约116倍。针对基于3-D FNO网络的三维热传导问题求解任务,异构训练方法相对全精度数字计算在节约22%的训练时间的同时,训练精度损失仅为7.3×10-4,相较全忆阻原位训练则可将训练延时与功耗开销降低至1/4(图2)。研究成果验证了忆阻存算一体技术在高精度神经网络求解器中的应用潜力,为推动发展面向AI-for-Science领域的非冯计算系统提供了重要基础。
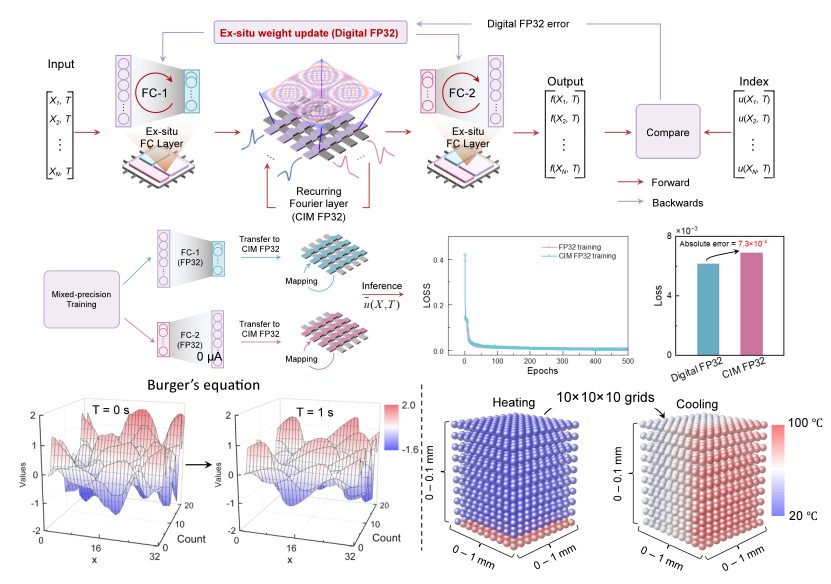
图2. 基于忆阻智能计算系统的FNO训练,
实现Burger’s 方程及3D热导问题的高精度高能效求解
我校集成电路学院李祎教授和清华大学集成电路学院高滨教授为论文的共同通讯作者。华中科技大学集成电路学院博士毕业生李健聪(现于香港科技大学从事博士后研究)、博士生田婧和清华大学集成电路学院博士后林钰登为论文共同第一作者,香港智能晶片与系统研发中心陈佳博士、华中科技大学集成电路学院何毓辉教授等人参与了本工作。
该工作得到了科技创新2030“脑科学与类脑研究”重大研究计划、科技部国家重点研发计划、湖北省杰出青年基金、华中科技大学基础研究支持计划等项目的资助,以及华中科技大学国家集成电路产教融合平台、北京未来芯片技术高精尖创新中心的支持。